Gratuitous ARP in OpenStack Neutron with ML2/OVS - Part 2
A OpenStack ML2/OVS trip to kernel gratuitous ARP packet handling code and back.
This is a continuation of the second post in the series on GARP and Neutron. For the first part, see here.
I’m not actually good at computers I’m just bad at giving up. // mjg59
It’s OpenStack fault
Failure mode
It was two months before the next shiny Ocata-based release of Red Hat OpenStack Platform (RH-OSP 11). Now that the team focus shifted from upstream development to polishing the product, we started looking more closely at downstream CI jobs. As usual with new releases, there were several failures in our tempest jobs. For most of them we figured out a possible culprit and landed fixes. For most of them, except The Failure.
Well, it was not a single test case that was failing, more like a whole class of them. In those affected test jobs, we execute all tempest tests, both api and scenario, and what we noticed is that a lot of scenario test cases were failing on connectivity checks when using a floating IP (but, importantly, never a fixed IP). Only positive connectivity checks were failing (meaning, cases where connectivity was expected but failed; never a case where lack of connectivity was expected).
There are two types of connectivity checks in tempest: ping check and SSH check. The former sends ICMP (or ICMPv6) datagrams to an IP address under test for 120 seconds and expects a single reply, while the latter establishes a SSH session to the IP address and waits for successful authentication.
In the failing jobs, whenever a ping check failed, the following could be seen in the tempest log file:
1
2
3
4
5
6
7
2017-05-06 00:02:32.563 3467 ERROR tempest.scenario.manager Traceback (most recent call last):
2017-05-06 00:02:32.563 3467 ERROR tempest.scenario.manager File "/usr/lib/python2.7/site-packages/tempest/scenario/manager.py", line 624, in check_public_network_connectivity
2017-05-06 00:02:32.563 3467 ERROR tempest.scenario.manager mtu=mtu)
2017-05-06 00:02:32.563 3467 ERROR tempest.scenario.manager File "/usr/lib/python2.7/site-packages/tempest/scenario/manager.py", line 607, in check_vm_connectivity
2017-05-06 00:02:32.563 3467 ERROR tempest.scenario.manager self.fail(msg)
2017-05-06 00:02:32.563 3467 ERROR tempest.scenario.manager File "/usr/lib/python2.7/site-packages/unittest2/case.py", line 666, in fail
2017-05-06 00:02:32.563 3467 ERROR tempest.scenario.manager raise self.failureException(msg)
When it was a SSH check that failed, then the error looked a bit different:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh Traceback (most recent call last):
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh File "/usr/lib/python2.7/site-packages/tempest/lib/common/ssh.py", line 107, in _get_ssh_connection
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh sock=proxy_chan)
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh File "/usr/lib/python2.7/site-packages/paramiko/client.py", line 305, in connect
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh retry_on_signal(lambda: sock.connect(addr))
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh File "/usr/lib/python2.7/site-packages/paramiko/util.py", line 269, in retry_on_signal
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh return function()
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh File "/usr/lib/python2.7/site-packages/paramiko/client.py", line 305, in
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh retry_on_signal(lambda: sock.connect(addr))
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh File "/usr/lib64/python2.7/socket.py", line 224, in meth
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh return getattr(self._sock,name)(*args)
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh timeout: timed out
2017-05-05 21:29:41.996 4456 ERROR tempest.lib.common.ssh
2017-05-05 21:29:41.997 4456 ERROR tempest.scenario.manager [-] (TestGettingAddress:test_multi_prefix_dhcpv6_stateless) Initializing SSH connection to 10.0.0.214 failed. Error: Connection to the 10.0.0.214 via SSH timed out.
If you would pick a single test case that sometimes failed, it didn’t have a high risk to impact job results, but once you aggregate all failures from all affected test cases, the chance of successfully passing the whole test run became abysmal, around 10%, which was clearly not ideal.
So I figured I may have a look at that, naively assuming it will take a day or two to find the root cause, fix it and move on with my life. Boy I was wrong! It took me a month to get to the bottom of it (though in all honesty, most of the time was spent trying to setup environment that would consistently reproduce the issue).
First steps
Initially, I figured failures are most often happening in our L3 HA jobs, so I focused on one of those. Reading through tempest, neutron-server, neutron-openvswitch-agent, and neutron-l3-agent log files hasn’t revealed much.
When looking at a particular test failure, we could see that the instance that was carrying the failing floating IP successfully booted and received a DHCPv4 lease for its fixed IP, as seen in its console log that tempest gladly dumps on connectivity check failures:
1
2
3
4
5
Starting network...
udhcpc (v1.20.1) started
Sending discover...
Sending select for 10.100.0.11...
Lease of 10.100.0.11 obtained, lease time 86400
To cross-check, we could also find the relevant lease allocation event in the system journal:
1
2
May 06 06:02:57 controller-1.localdomain dnsmasq-dhcp[655233]: DHCPDISCOVER(tap7876deff-b8) fa:16:3e:cc:2c:30
May 06 06:02:57 controller-1.localdomain dnsmasq-dhcp[655233]: DHCPOFFER(tap7876deff-b8) 10.100.0.11 fa:16:3e:cc:2c:30
The tempest log file clearly suggested that the failure was not because of a SSH key pair misbehaving for the failing instance. If that would be a public SSH key pair not deployed to the instance, we would not see SSH timeouts but authentication failures. Neither we saw any SSH timeouts for tests that established SSH sessions using internal fixed IP addresses of instances.
It all suggested that internal (“tenant”) network connectivity worked fine. The problem was probably isolated somewhere in Neutron L3 agent. But looking into Neutron L3 agent and neutron-server logs hasn’t surfaced any problem either: we could easily find relevant arping calls in Neutron L3 agent (for L3 legacy routers) or the system journal (for Neutron L3 HA routers).
Of course, you never believe that a legit fault may be a result of software that is external to your immediate expertise. It’s never compiler or other development tool fault; 99% of whatever you hit each day is probably your fault. And in my particular case, it was, obviously, OpenStack Neutron that was guilty. So it took me awhile to start looking at other places.
But after two weeks of unproductive code and log reading and adding debug statements in Neutron code, it was finally time to move forward to unknown places.
Beyond OpenStack
Deployment
Before diving deeper, let’s make a step back and explore the deployment more closely. How are those floating IP addresses even supposed to work in this particular setup? Is the tempest node on the same L2 network segment with the floating IP range, or is it connected to it via a L3 router?
The failing jobs deploy Red Hat OpenStack using Director also known as TripleO. It’s not a very easy task to deploy a cloud using bare TripleO, and for this reason there are several tools that prepare development and testing environments. One of those tools is tripleo-quickstart, more popular among upstream developers, while another one is Infrared, more popular among CI engineers. The failing jobs were all deployed with Infrared.
Infrared is a very powerful tool. I won’t get into details, but to give you a taste of it, it supports multiple compute providers allowing to deploy the cloud in libvirt or on top of another OpenStack cloud. It can deploy both RH-OSP and RDO onto provisioned nodes. It can use different installers (TripleO, packstack, …). It can also execute tempest tests for you, collect logs, configure SSH tunnels to provisioned nodes to access them directly… Lots of other cool features come with it. You can find more details about the tool in its documentation.
As I said, the failing jobs were all deployed using Infrared on top of a powerful remote libvirt hypervisor where a bunch of nodes with distinct roles were created:
- a single “undercloud” node that is used to provision the actual “overcloud” multinode setup (this node also runs
tempest); - three “overcloud” controllers all hosting Neutron L3 agents;
- a single “overcloud” compute node hosting Nova instances.
All the nodes were running as KVM guests on the same hypervisor, connected to each other with multiple isolated libvirt networks, each carrying a distinct type of traffic. After Infrared deployed “undercloud” and “overcloud” nodes, it also executed “neutron” set of tests that contains both api and scenario tests, from both tempest and neutron trees.
As I already mentioned, the “undercloud” node is the one that also executes tempest tests. This node is connected to an external network that hosts all floating IP addresses for the preconfigured public network, with eth2 of the node directly plugged into it. The virtual interface is consequently plugged into the hypervisor external Linux kernel bridge, where all other external (eth2) interfaces for all controllers are plugged too.
What it means for us is that the tempest node is on the same network segment with all floating IP addresses and gateway ports of all Neutron routers. There is no router between the floating IP network and the tempest node. Whenever a tempest test case attempts to establish an SSH connection to a floating IP address, it first consults the local ARP table to possibly find an appropriate IP-to-MAC mapping there, and if the mapping is missing, it will use the regular ARP procedure to retrieve the mapping.
Now that we understand the deployment, let’s jump into the rabbit hole.
Traffic capture
The initial debugging steps on OpenStack Neutron side haven’t revealed anything useful. We identified that Neutron L3 agent correctly called to arping with the right arguments. So in the end, maybe it’s not OpenStack fault?
First thing to check would be to determine whether arping actually sent gratuitous ARP packets, and that they reached the tempest node, at which point we could expect that the “undercloud” kernel would honor them and update its ARP table. I figured it’s easier to only capture external (eth2) traffic on the tempest node. I expected to see those gratuitous ARP packets there, which would mean that the kernel received (and processed) them.
Once I got my hands on hardware capable of standing up the needed TripleO installation, I quickly deployed the needed topology using Infrared.
Of course, it’s a lot easier to capture the traffic on tempest node but analyze it later in Wireshark. So that’s what I did.
1
$ sudo tcpdump -i eth2 -w external.pcap
I also decided it may be worth capturing ARP table state during a failed test run.
1
$ while true; do date >> arptable; ip neigh >> arptable; sleep 1; done
And finally, I executed the tests. After 40 minutes of waiting for results, one of tests failed with the expected SSH timeout error. Good, time to load the .pcap into Wireshark.
The failing IP address was 10.0.0.221, so I used the following expression to filter the relevant traffic:
1
ip.addr == 10.0.0.221 or arp.dst.proto_ipv4 == 10.0.0.221
The result looked like this:

Here, we see the following: first, SSH session is started (frame 181869), it of course initially fails (frame 181947) because gratuitous ARP packets start to arrive later (frames 181910, 182023, 182110). But then for some reason consequent TCP packets are still sent using the old 52:54:00:ac:fb:f4 destination MAC address. It seemed like arriving gratuitous ARP packets were completely ignored by the kernel. More importantly, the node continued sending TCP packets to 10.0.0.221 using the old MAC address even past expected aging time (60 seconds), and it never issued a single ARP REQUEST packet to update its cache throughout the whole test case execution (!). Eventually, after ~5 minutes of banging the wrong door the test case failed with a SSH timeout.
How could it happen? The kernel is supposed to honor the new MAC address right after it receives an ARP packet!
Now, if we would compare the traffic dump to a successful test case run, we could see the traffic capture that looked more like below (in this case, the IP address of interest is 10.0.0.223):

Here we see TCP retransmission of SSH, port 22, packets (74573 and 74678), which failed to deliver because the kernel didn’t know the new fa:16:3e:bd:c1:97 MAC address just yet. Later, we see a burst of gratuitous ARP packets sent from the router serving 10.0.0.223, advertising the new MAC address (frames 74715, 74801, and 74804). Though it doesn’t immediately suggest that these were gratuitous ARP packets that healed the connectivity, it’s clear that the tempest node quickly learned about the new MAC address and continued with its SSH session (frames 74805 and forward).
One thing that I noticed while looking at multiple traffic captures from different test runs is that whenever a test failed, it always failed on a reused floating IP address. Those would show up in Wireshark with the following warning message:

State transitions
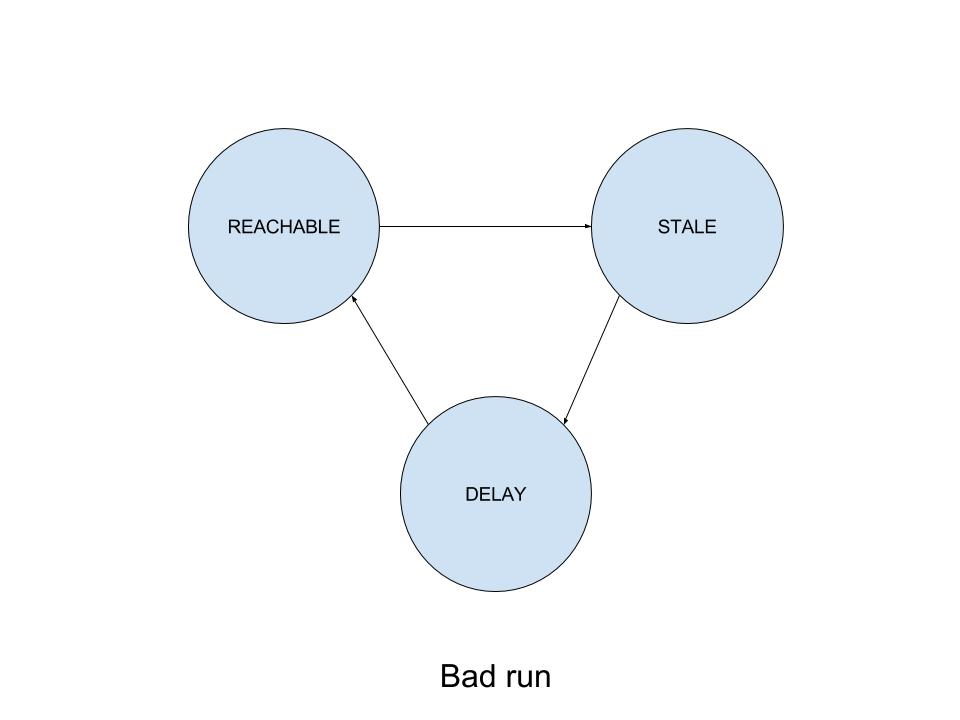
Then maybe there was a difference in ARP entry state between successful and failing runs? Looking at the ARP table state dumps I collected during a failing run, the following could be said:
- Before the start of the failed test case, the corresponding ARP entry was in STALE state.
- Around the time when gratuitous ARP packets were received and the first TCP packet was sent to the failing IP address, the entry transitioned to DELAY state.
- After 5 seconds, it transitioned to REACHABLE without changing its MAC address. No ARP REQUEST packets were issued in between.
- The same STALE - DELAY - REACHABLE transitions were happening for the affected IP address over and over. The
tempestnode hasn’t issued a single ARP REQUEST during the whole test case execution. Neither it received any new traffic that would use the old MAC address.
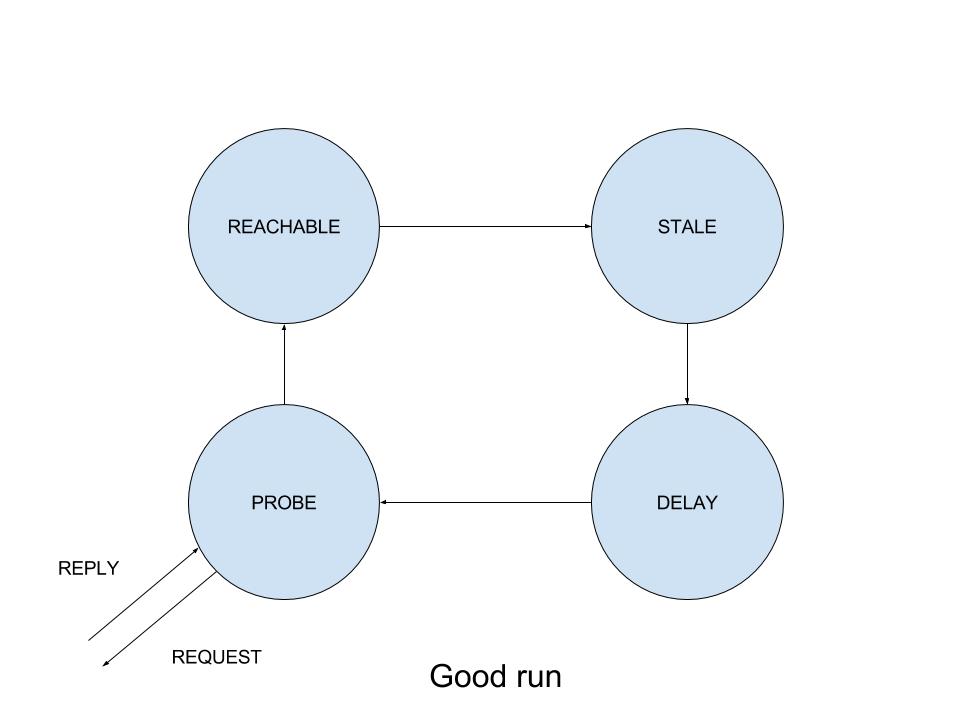
If we compare this to ARP entries in ”good” runs, we see that there they also start in STALE state, then transition to DELAY, but after 5 seconds, instead of transitioning to REACHABLE, it switched to PROBE state. The node then issued a single ARP REQUEST (could be seen in the captured traffic dump), quickly received a reply from the correct Neutron router, updated the ARP entry with the new MAC address, and only then finally transitioned to REACHABLE. At this point the connectivity healed itself.
What made the node behave differently in those two seemingly identical cases? Why hasn’t it issued a ARP probe in the first case? What are those ARP table states anyway? I figured it was time to put my kernel hat on and read some Linux code.
Diggin’ the Kernel
In my previous life, I was a Linux kernel developer (nothing fancy, mostly enabling embedded hardware). Though this short experience made myself more or less comfortable with reading the code, I figured I could use some help from the vast pool of Red Hat kernel developers. So I reached to Lance Richardson who, I was told, could help me figure out what’s going on with the Failure. And indeed, his help was enormous. In next several days, we discussed the kernel code on IRC, were digging old kernel mailing list archives, built and tested a bunch of custom kernels with local modifications to its networking layer. Here is what we’ve found.
Gratuitous ARP with arp_accept
Since RHEL7 kernel is quite old (3.10.0-514.22.1.el7 at the time of writing), we decided to start our search by looking at patches in Linus master branch and see if there were any that could be of relevance to the Failure, and that were not backported yet into RHEL7 kernel. The primary files of interest in the kernel source tree were net/ipv4/arp.c (the ARP layer) and net/core/neighbour.c (the neighbour layer which is an abstract representation of address-to-MAC mappings used for IPv4 as well as for IPv6).
Digging through the master branch history, the very first patch that drew our attention was: “ipv4: arp: update neighbour address when a gratuitous arp is received…” What the patch does is it forces override of an existing ARP table entry when a gratuitous ARP packet is received irrespective of whether it was received in locktime time interval. It is effective only when arp_accept is enabled, which is not the default. Anyway, that ringed some bell, and also suggested that maybe we dealt with a timing issue. The patch assumed arp_accept enabled and temporarily disabled the locktime behavior for gratuitous ARP packets, so let’s have a closer look at those two sysctl knobs.
Here is the documentation for the arp_accept sysctl knob. The setting controls whether the kernel should populate its ARP table with new entries on receiving ARP packets if the IP addresses are not registered in the table yet. Enabling the setting may be useful if you want to “warm up” the ARP table on system startup without waiting for the node to send its very first datagram to an IP address. The idea is that the kernel will listen for any ARP packets flying by, and it will create new table entries for previously unseen IP addresses. The default for the option is 0 (meaning off), and that’s for a reason. Enabling the feature may have unexpected consequences because the size of the kernel ARP table is limited, and in large network segments it may happen that the kernel will overflow the table with irrelevant entries due to the “warming up”. If that ever happens, the kernel may then start dropping some table entries that may still be useful. If that happens, you can see slowdown for some upper layer protocol connections for the time needed to restore the needed ARP entries using a round-trip of ARP probe packets. Long story short, the arp_accept setting is not for everyone.
As for locktime, there seems to be no in-tree documentation for the sysctl parameter, so the best source of information is probably arp(7). Quoting:
1
2
3
[locktime is] the minimum number of jiffies to keep an ARP entry in the cache.
This prevents ARP cache thrashing if there is more than one potential mapping
(generally due to network misconfiguration). Defaults to 1 second.
What it means is that if an ARP packet arrives during a 1 second interval since the previous ARP packet, it will be ignored. This is helpful when using ARP proxies where multiple network endpoints can reply to the same ARP REQUEST. In this case, you may want to ignore those replies that arrive later (to avoid so called ARP thrashing, as well as to stick to the node that is allegedly quicker/closer to the node).
With the above mentioned kernel patch, and arp_accept set to 1, the kernel should always update its ARP table if a gratuitous ARP packet is received, even if the entry is still in the locktime time interval.
Though arp_accept is not applicable for everyone, it was still worth exploring. I backported the patch into RHEL7 kernel, rebooted the tempest node, enabled arp_accept for eth2, and rerun the tests. Result? Same failures. So why hasn’t it worked?
Code inspection of neigh_update hasn’t revealed anything interesting. Everything suggested that override was still false. It took me awhile, but then it struck me: the code to determine whether an ARP packet is gratuitous considered frames of Request type, but not Reply. And Neutron L3 agent sends Replies (note the -A option instead of -U used in the arping command line)! Here is how arping(8) defines those options:
1
2
-A The same as -U, but ARP REPLY packets used instead of ARP REQUEST.
-U Unsolicited ARP mode to update neighbours' ARP caches. No replies are expected.
The next step was clear: let’s try to switch all Neutron L3 agents to gratuitous ARP requests and see if it helps. So I applied a one-liner to all controller nodes, restarted neutron-l3-agent services, and repeated the test run. It passed. I even passed multiple times in a row, first time in a long time I was banging my head over the issue!
OK, now I had a workaround. To pass tests, all I needed was:
- Get a kernel that includes the patch (officially released as
3.14on Mar 30, 2014); - Enable
arp_acceptfor the external (eth2) interface; - Restart
neutron-l3-agentservices with the one-liner included.
But does it make sense that the kernel accepts gratuitous REQUESTs but not REPLYs? Is there anything in RFCs defining ARP that would suggest REPLYs are a different beast? Let’s have a look.
As we’ve learned in the very first post in the series, gratuitous ARP packets are defined in RFC 2002. Let’s quote the definition here in full.
1
2
3
4
5
6
7
8
9
10
11
A Gratuitous ARP [23] is an ARP packet sent by a node in order to
spontaneously cause other nodes to update an entry in their ARP
cache. A gratuitous ARP MAY use either an ARP Request or an ARP
Reply packet. In either case, the ARP Sender Protocol Address
and ARP Target Protocol Address are both set to the IP address
of the cache entry to be updated, and the ARP Sender Hardware
Address is set to the link-layer address to which this cache
entry should be updated. When using an ARP Reply packet, the
Target Hardware Address is also set to the link-layer address to
which this cache entry should be updated (this field is not used
in an ARP Request packet).
So clearly both gratuitous ARP “flavors”, REQUEST and REPLY, are defined by the standard. There should be no excuse for the kernel to handle valid gratuitous REPLY packets in any other way than REQUESTs. To fix the wrongdoing, I posted a patch that makes the kernel to honor gratuitous REPLYs the same way as it does REQUESTs. (The patch is now merged in netdev master.)
Even though the kernel fix landed and will probably be part of the next 4.12 release, OpenStack Neutron still needs to deal with the situation somehow for the sake of older kernel, so it probably makes sense to issue REQUESTs from Neutron L3 agents to help those who rely on arp_accept while using an official kernel release. The only question is, should we issue both REQUESTs and REPLYs, or just REQUESTs? For Linux network peers, REQUESTs work just fine, but is there a risk that some other networking software stack honors REPLYs but not REQUESTs?.. To stay on safe side, we decided to issue both.
Anyhow, we discussed before that arp_accept is not for everyone, and there is a good reason why it’s not enabled by default. OpenStack should work irrespective of the sysctl knob value set on other network hosts, that’s why the patches mentioned above couldn’t be considered a final solution.
Besides, arp_accept only disabled locktime mechanism for gratuitous ARP packets, but we haven’t seen any ARP packets before the first gratuitous packet arrived. So why hasn’t the kernel honored it anyway?
Locktime gets in the way of GARPs
As we’ve already mentioned, without arp_accept enforcement, neigh_update hasn’t touched the MAC address for the corresponding ARP table entry. Code inspection suggested that the only case when it could happen was if arp_process passes flags==0 and not flags==NEIGH_UPDATE_F_OVERRIDE into neigh_update. And in the RHEL 7.3 kernel, the only possibility for that to happen is when all three gratuitous ARP replies would arrive in locktime time interval.
But they are sent with a 1-second interval between them, and the default locktime value is 1 second too, so at least the last, or even the second packet in the 3-set should have affected the kernel. Why hasn’t it?..
Let’s look again at how we determine whether an update arrived during the locktime:
1
override = time_after(jiffies, n->updated + n->parms->locktime);
What the quoted code does is it checks whether an ARP packet is received in n->updated..n->updated + n->params->locktime time interval, where n->params->locktime == 100. And what does n->updated represent?
If override is false, call to neigh_update will bail out without updating the MAC address or the ARP entry state. But see what it does just before bailing out: it sets n->updated to current time!
So what happens is that the first gratuitous ARP in the 3-series arrives in locktime interval; it calls neigh_update with flags==0 that updates n->updated and bails out. By moving n->updated forward, it also effectively moves forward the locktime window without actually handling a single frame that would justify that! The next time the second gratuitous ARP packet arrives, it’s again in the locktime window, so it again calls neigh_update with flags==0, which again moves the locktime window forward, and bails out. The exact same story happens for the third gratuitous ARP packet we send from Neutron L3 agent.
So where are we at the end of the scenario? The ARP entry never changed its MAC address to reflect what we advertised with gratuitous ARP replies, and the kernel networking stack is not aware of the change.
This moving window business didn’t seem right to me. There is a reason for locktime, but its effect should not take longer than its value (1 second), and this was clearly not what we’ve seen. So I poked the kernel a bit more and came up with a patch that avoids updating n->updated if neither entry state nor its MAC address would change on neigh_update. With the patch applied to RHEL kernel, I was able to pass previously failing test runs without setting arp_accept to 1. Great, seems like now I had a proper fix!
(The patch is merged, and will be part of the next kernel release. And in case you care, here is the bug for RHEL kernel to fix the unfortunate scenario.)
But why would kernel even handle gratuitous ARP differently for existing ARP table entries depending on arp_accept value? The sysctl setting was initially designed to only control behavior when an ARP packet for a previously unseen IP address was processed. So why the difference? In all honesty, there is no reason. It’s just a bug that sneaked into the kernel in the past. We figured it makes sense to fix it while we are at it, so I posted another kernel patch (this required some reshuffling and code optimization, hence the patch series). With the patch applied, all gratuitous ARP packets will now always update existing entries. (And yes, the patch is also merged and will be part of the next release.)
Of course, a careful reader may wonder why locktime even considers entry state transitions and not just actual ARP packets that are received on the wire, gratuitous or not. That’s a fair question, and I believe that the answer here is, “that’s another kernel bug”. That being said, brief look at the kernel code suggests that it won’t be too easy to make it work the way it should. It would require major rework of kernel neigh subsystem to make it track state transitions independently of MAC/IP transitions. I figured I better leave it to later (also known as never).
How do ARP table states work?
So at this point it seems like I have a set of solutions for the problem.
But one may ask, why has the very first gratuitous ARP packet arrived during locktime? If we look at the captured traffic, we don’t see any ARP packets before the gratuitous ARP burst.
But it turns out that you can get n->updated bumped even without a single ARP packet received! But how?
The thing is, the neighbour.c state machine will update the timestamp not just when a new ARP packet arrives (which happens through arp_process calling to neigh_update), but also when an entry transitions between states, and state transitions may be triggered from inside the kernel itself.
As we already mentioned before, the failing ARP entry cycles through STALE - DELAY - REACHABLE states. So how do entries transition to DELAY?
As it turned out, the DELAY state is used when an existing STALE entry is consumed by an upper layer protocol. Though it’s STALE, it still can be used to connect to the IP address. What kernel does is, on the first upper layer protocol packet sent using a STALE entry, the entry is switched to DELAY, and a timer is set for +delay_first_probe_time in the future (5 seconds by default). When the timer is fired, the kernel then checks whether any upper layer protocol confirmed the entry as reachable. If it is confirmed, the kernel merely switches the state of the entry to REACHABLE; if it’s not confirmed, the kernel issues an ARP probe and updates its table with the result.
Since we haven’t seen a single probe sent during the failing test run, the working hypothesis became - the entry was always confirmed in those 5 seconds before the ARP probe, so the kernel never needed to send a single packet to refresh the entry.
But what is this confirmation anyway?
ARP confirmation
The thing is, it’s probably not very effective to immediately drop existing ARP entries when they become STALE. In most cases, those IP-to-MAC mappings are still valid even after the aging time: it’s not too often that IP addresses move from one device to another. So it would be not ideal if we would need to repeat ARP learning process each time an entry expires (each minute by default). It would be even worse if we would need to pause all other connections to an IP address whenever an ARP entry currently in use becomes STALE, to wait until the ARP table is updated. Since upper layer protocols (TCP, UDP, SCTP, …) may already successfully communicate with the IP address, we can use their knowledge about host availability and avoid unneeded probes, connectivity flips and pauses.
For that matter, Linux kernel has the confirmation mechanism. A lot of upper layer protocols support it, among those are TCP, UDP, and SCTP. Here is a TCP example. Whenever the confirmation aware protocol sees an incoming datagram from the MAC address using the IP address, it confirms the mapping to ARP layer, which then bails out of ARP probing and silently moves the entry to REACHABLE whenever the delay timer fires up.
Scary revelations
And what is this dst that is confirmed by calling to dst_confirm? It’s a pointer to a struct dst_entry. This structure defines a single cached routing entry. I won’t describe in details what it is, and how it’s different from struct fib_info that is an uncached routing entry (better explained in other sources).
What’s important for us to understand is that the entry may be not unique for a particular IP address. As long as outgoing packets take the same routing path, they may share the same dst_entry. And all the traffic directed to the same network subnet reuses the same routing path.
Which means that all the traffic directed from a controller node to the tempest node using any floating IP may potentially “confirm” any of ARP entries that belong to other IP addresses from the same range!
Since tempest tests are executed in parallel, and a lot of them send packets using a confirmation aware upper layer protocol (specifically, TCP for SSH sessions), ARP entries can effectively live throughout the whole test case run cycling through STALE - DELAY - REACHABLE states without issuing a single probe OR receiving any matching traffic for the IP/MAC pair.
And that’s how old MAC addresses proliferate. First we ignore all gratuitous ARP replies because of locktime; then we erroneously confirm wrong ARP entries.
And finally, my Red Hat kernel fellows pointed me to the following patch series that landed in 4.11 (released on May 1, 2017, just while I was investigating the failure). The description of the series and individual patches really hits the nail, for it talks about how dst_entry is shared between sockets, and how we can mistakenly confirm wrong ARP entries because of that.
I tried the patch series out. I reverted all my other kernel patches, then cherry-picked the series (something that is not particularly easy considering RHEL is still largely at 3.10, so for reference I posted the result on github), rebooted the system, and retried tests.
They passed. They passed over and over.
Of course, the node still missed all gratuitous ARP replies because of moving locktime window, but at least the kernel later realized that the entry is broken and requires a new ARP probe, which was correctly issued by the kernel, at which point the reply to the probe healed the cache and allowed tests to pass.
Great, now I had another alternative fix, and it was already part of an official kernel release!
The only problem with backporting the series is that the patches touch some data structures considered part of kernel ABI, so just putting the patches from the series into the package as-is triggered a legit KABI breakage during RPM build. For testing purposes, it was enough to disable the check but if we were going to backport the series into RHEL7, we needed some tweaks to the patches to retain binary compatibility (which is one of RHEL long term support guarantees).
For the reference, I opened a bug against RHEL7 kernel to deal with bogus ARP confirmations. At the time of writing, we hope to see it fixed in RHEL 7.4.
And that’s where we are. A set of kernel bugs combined - some new, some old, some recently fixed - produced the test breakage. If any of those bugs were not present in the environment, tests would have a chance to pass. Only the combination of small kernel mistakes and major screw-ups hit us hard enough to dig deep into the kernel.
Summary
We finally learned what went wrong with the Failure, and we figured there is no OpenStack fault in it. Instead, it is Linux kernel that ignores all gratuitous ARP packets Neutron L3 agent eagerly sends its way; and it is the same Linux kernel that is spinning bogus ARP entries in perpetual STALE – DELAY – REACHABLE state change loop without a way out.
And that’s where we are at. We have the following alternatives to tackle the test failure problem.
- Get a kernel that includes the garp enforcing patch;
- Enable
arp_acceptfor the external (eth2) interface; - Restart
neutron-l3-agentservices with the switch to ARP requests included;
…or…
- Include the patch that avoids touching
n->updatedif an ARP packet is ignored;
…or…
- Include the patch that forces override for all gratuitous ARP packets irrespective of
arp_accept;
…or…
- Include the series of patches to fix ARP confirmation.
(Of course, ideally all of those pieces would find their way into your setup.)
All of those solutions currently require kernel backports, at least for RHEL7. In the meantime, could we do something just on Neutron side? On first sight, it sounds like a challenge. But when you think about it, we can use the knowledge about the failure mode to come up with a workaround that may work in most cases.
We know that the issue would not show itself up in tests if only any of gratuitous ARP replies sent by Neutron would be honored by kernel, and they are all ignored because of arrival during locktime window.
We know that the default value for locktime is 1 second, and the reason why all three gratuitous ARP packets are ignored is because each of them land into the moving locktime window, which happens because of the way we issue those packets using the arping tool. The default interval between gratuitous ARP packets issued by the tool is 1 second, but if we could make it longer, it could help the kernel to get out of the moving locktime window loop and honor one of packets sent in burst.
From looking at arping(8) and its code, it doesn’t seem like it supports picking an alternative interval with any of its command line options (I have sent a pull request to add the feature but it will take time until it gets into distributions). If we want to spread gratuitous updates in time using arping, we may need to call the tool multiple times from inside Neutron L3 agent and maintain time interval between packets ourselves.
Here is the Neutron patch to use this approach. This would of course work only with hosts that don’t change locktime sysctl setting from its default value. Moreover, it’s very brittle, and may still not give us 100% test pass guarantee.
The chance of success can of course be elevated by setting arp_accept on all nodes. The good news is that at least some OpenStack installers already do it. For example, see this patch for Fuel. While the original reasoning behind the patch is twisted (gratuitous ARP packets are accepted irrespective of arp_accept, it’s just that locktime may get in their way in bad timing), the change itself is still helpful to overcome limitations of released kernels. To achieve the same effect for TripleO, I posted a similar patch.
Finally, note that while all the workarounds listed above may somewhat help with passing tempest tests, without the patch series tackling the very real spurious confirmation issue, you still risk getting your ARP table broken without a way for it to self-heal.
The best advice I can give is, make sure you use a kernel that includes the patch series (all official kernels starting from 4.11 do). If you consume kernel from a distribution, talk to your vendor to get the patches included. Without them, you risk with your service availability. (To note, while I was digging this test only issue, we got reports from the field some ARP entries were staying invalid for hours after failover.)
And finally… it’s not always an OpenStack fault. Platform matters.